
AI Drum Loop Generation
Finding myself using the same handful of drum tracks over and over again from a Native Instruments pack I bought in 2012 I decided to head back into the world of RNNs.
Leaning on my notes from the SNES midi generator, which in a powerful display of irony, were originally based on the instructions for the magenta drum generator, not the polyphony one that project actually uses, I got the framework set up in no time. As a side note; this post is nothing more than a copy of that article, with some added notes on midi mappings.

What followed was a lot of effort to wrangle my input data, which is where the big learning for RNNs arose; what goes in is far more important than how its being processed. Utilising the magic black box without understanding whats going on under the hood (they are called HIDDEN layers after all) seems to be of zero detriment to any of the projects I have put together.
This fucking stumped me for a few days; my data was being processed by magentas polyphony dataset creator, but not by the drum one. Which actually might be an interesting expirment, to see what it would even come up with. But I wanted actual usable drum tracks, not aborted expirments, so that can wait for another day. The issue, it turns out, was midi mappings. I use the Native Instruments stuff (for no other reason than I paid actual money for it from a very expensive overpriced music shop in Casuarina that no longer exists after watching Rock of Ages), which has a different mapping to Drummer From Hell, which has a different mapping to EZdrummer, which has a different mapping to something known as ‘general midi’, or GM. Which as it turns out, was the input mapping required for the drums dataset creator.
But what is a midi mapping? It’s corresponding certain drum kit bits with certain notes on a piano. C3, for instance, in EZdrummer is a kick, snare in Drummer From Hell and the Native Instruments stuff (which is what I use), and a crash in GM. Mapping, the midi drums to piano keys.
Why they all take it upon themselves to lay out the same fucking thing in different ways is beyond me. I asked ChatGPT for some reasons why and it essentially came up with “lol cause they did it that way”. Helpful.

Now this posed a significant challenge; all my midi files were already in the mapping for the Studio Drummer/Abbey Road plugins (the Abbey Road 80s drummer sounds really great to me. Well worth the money for those insane reverb kicks.) So how do we turn it into this “general mapping” mapping?
By painstakingly rewriting the midi files thats how. And that most certainly wasn’t going to happen. So I went and purchased (lol) a new set of drum loops. This collection came with the loops already in every mapping under the sun, including GM.

Everything was NOW working fine. The datasets were being created correctly, and we are able to begin. The first run took 2 hours, and looks like this. You don’t need to hear it to know this is shit. It’s wonky and can’t keep a beat. So how should we improve this?
I asked my good friend chatgpt for assistance here. We increased the batch size and increased the number of units in each layer. Thats because my dataset was 3500 items, and the intial values of batch size of 128 and layer unit count of 64 were just not enough to really capture the complexity of the data sets patterns. Which was what I really wanted; I cant program drums because I dont really understand what makes a good drum sound; I need this if/else generator to do the heavy lifting for me. I also decided to double the training steps. I figured if 1000 took 2 hours, 2000 would take 4, then doubled for a max of 8.
Now I had ASSUMED with my tiny man brain that by doubling the layer size, we would see a double in effort time right? No. It increased by a literal order of magnitude. It took two days to complete in the end. ~40 hours.

But I wanted to monitor what it was doing, and paused it every so often to see what it was sounding like. Here are the improvements. As you can see, it very quickly started to improve. The doubling of the layer sizes REALLY honed it in on what I was after.
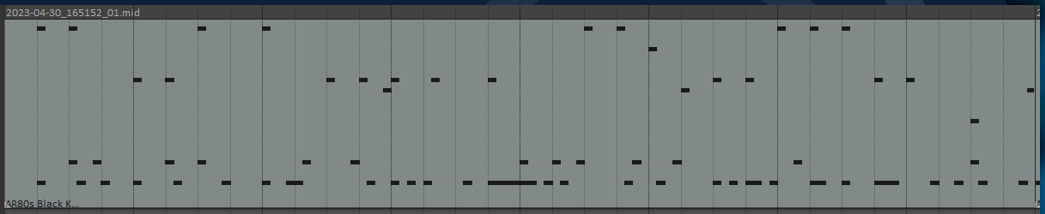
 That was after 1277 checkpoints, so I think it had been just over 8 hours since starting?
That was after 1277 checkpoints, so I think it had been just over 8 hours since starting?
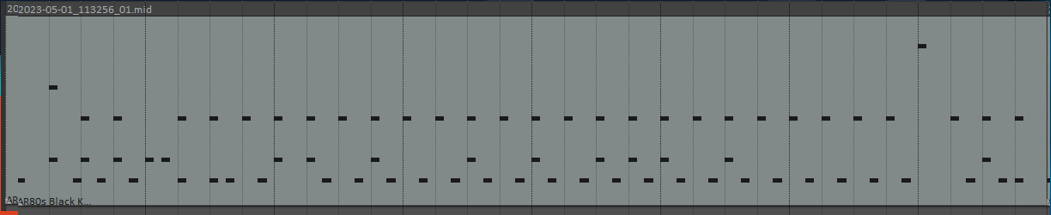
 This was checkpoint 1889, which was I assume about a little under halfway through the process.
This was checkpoint 1889, which was I assume about a little under halfway through the process.
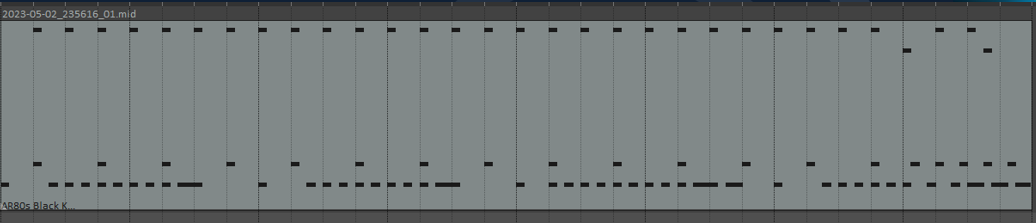 Finally we have results once all 2000 steps have been completed. Look at that, on the beat every beat. This was 4074 checkpoints.
Finally we have results once all 2000 steps have been completed. Look at that, on the beat every beat. This was 4074 checkpoints.
One more comparison might highlight just how much it improved; the top is after using the smaller model and the bottom is the last model. Much, much better.
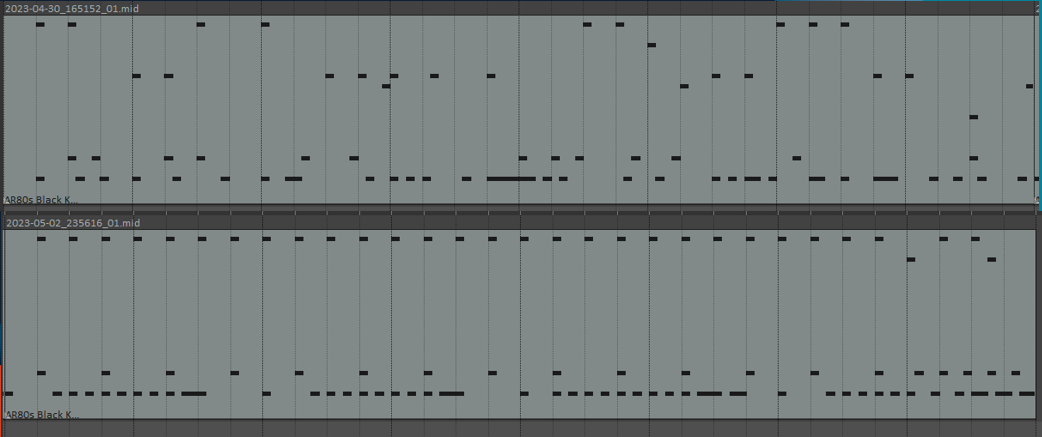
Taking two days to complete however, maybe its time I get some new budget, discounted gear..

These rough notes are included simply so I can look up quickly how to do this again, they probably wont help you at all, ficticious reader.
1) turn drums into midi
convert_dir_to_note_sequences --input_dir="D:\zzzDrum Files\zzzmidi files\06_GM_tracks\metal_gm_only" --output_file="D:\zzzDrum Files\note sequences\06_GM_tracks\metal_gm_only.tfrecord" --recursive
2) create training set
drums_rnn_create_dataset --config="drum_kit" --input="D:\zzzDrum Files\note sequences\06_GM_tracks\metal_gm_only.tfrecord" --output_dir="D:\zzzDrum Files\dataset\06_GM_tracks\metal_gm_only\sequence_examples" --eval_ratio=0.10
3) train
drums_rnn_train --config="drum_kit" --run_dir="D:\zzzDrum Files\models\06_GM_tracks\metal_gm_only\run4_ACTUALLY_finish_cycle" --sequence_example_file="D:\zzzDrum Files\dataset\06_GM_tracks\metal_gm_only\sequence_examples\training_drum_tracks.tfrecord" --hparams="batch_size=256,rnn_layer_sizes=[128,128]" --num_training_steps=2000
4) generate
drums_rnn_generate --config=drum_kit --run_dir="D:\zzzDrum Files\models\06_GM_tracks\metal_gm_only\run4_ACTUALLY_finish_cycle" --hparams="batch_size=256,rnn_layer_sizes=[128,128]" --output_dir="D:\zzzDrum Files\yyy_generated\bigger_model\batch3" --num_outputs=10 --num_steps=128 --primer_drums="[(36,)]"
It is important to note here because I did not think to think this; when increasing the size of your layers, you need to match the layer size in your generation inputs. I had some strange issues where I did not increase the rnn_layer_sizes in the generation from 64 when trying to generate from the 128 model. Same with your batch size, needs to be matchy matchy.
Much like the finalisation of the Vagrant AD Lab, this was done over my birthday. It always makes me feel better to complete a project when it rolls around. Anyway I decided to also purchase this guitar as a present for myself; I’ve been on the hunt for this particular one for over 15 years. The second it arrived in my hot little hands express from japan I laid down some tracks using my generated drums in MY HOUSE. And it felt fucking GOOD.

Everything is coming up milhouse this year that’s for sure.
