
A Shallow Dive into Transformers and Attention
I tried my absolute best to work in some robots in disguise and attention is all you need pun, but they all sucked so you get no alternative titles and a barely functional title as it is.
![]()
“In the context of machine learning, a “transformer” refers to a type of neural network architecture that excels at processing sequential data, such as text or audio, by leveraging an “attention” mechanism”
Well that certainly technically qualifies as an answer, but raises more questions! Namely, what is attention?
“Attention is a machine learning method that determines the importance of each component in a sequence relative to the other components in that sequence.”
OK, this makes some sense, sounds like how speed reading works (here is a good blog on it I paroosed some time ago from Tim Ferris that i can confirm does work (but i dont do it, i find joy in reading and do so slowly)). Essentially in any given sentence, there are words that provide more value to the overall meaning trying to be conveyed. Attention, in the ML sense, is a method used to do the same thing, work out which words are important.
This is pretty interesting; when we are taught to read there isnt a list of words that mean more than others at all times, its contextual. For instance: “a cat shat on my hat” vs “my cat shat on the hat”. If we look at the words my and a. Their placement in the sentence structure changes it entirely; one is a personal tragedy and the other is an amusing anecdote i would chuckle about, respectively.
I do not nor do I want an accessiable picture of a cat shitting on a hat, but instead enjoy my cat wearing a hat.

We are not taught that “my” or “a” holds more weight as a word, ie that instances of my are more “powerful” or deserve more “attention” (you getting it now?) than the word a, which is in itself another branch on this metaphor; a is a (lol) word and a letter and in some cases, a number. It is all contextual, and the models learn this context dependancy in the same way we do; by reading the current input and applying meaning at real time, unlike say linear regression where the model learns that the coffecient is equal to w and will always be equal to w, no matter the inputs.
But how does the NN do it?
Sentence is inputted.
Lets use “my cat shat on a hat”
The sentence is broken down into tokens.
How tokens are defined depends on how the creater of the network defined it. For this instance, we will use words as tokens.
This would look like ‘my’ ‘cat’ ‘shat’ ‘on’ ‘a’ ‘hat’
Each token is mapped to a unique numerical identifier based on the models vocab.
In this instance, we will pretend the mapping washed out like so (for illustrative purposes it is irrelevent).
'my' 27287
'cat' 28498
'shat' 47385
'on' 7265
'a' 27020
'hat' 3828
Each token id is converted to a dense vector (aka an embedding) to capture the meaning of it within the sentence.
Wait, what is an embedding? A trainable lookup table where each ID in the vocab corrpospondes with a row, and each row is a vector (array/list) of floating point numbers.
Vectors are randomly initialised at the start of training. During training, the model updates the vectors with similar usage patterns end up with similar embeddings. ie cat/dog might become closer, hat and helmet, shit and shat, onwards and upwards. The number of floats in each row is equal to the embedding size (which you set prior to training). For example the old BERT uses 768. Our fake example will use 3. Dense means that each element in the array must contain a value, unlike say IPV6 where you can just set :: and omitt part of your address. Elements in the array are usually (ie 99.9999% of the time) between -1 and 1.
'my' 27287 0.23 0.44 -0.008
'cat' 28498 0.72 -0.45 0.33
'shat' 47385 0.48 -0.92 0.16
'on' 7265 0.71 -0.33 0.04
'a' 27020 -0.77 0.88 0.29
'hat' 3828 -0.65 0.01 0.63
Once we have the words vectors from the table, we assign a positional encoding vector. This is important because despite the sentence being my cat shat on a hat, the vectors are not passed sequentially to the transformer; they are processed all at once! Without tagging the vectors to ensure they are reassembled in the right order (think TCP) we could end up looking at the wrong sentence, ie on a hat shat my cat (ok bad example because that actually still works lmfao)
These are not tacked onto the end, a bunch of functions are performed against the inputs. I am not going to detail them because I a) dont understand them and b) as people smarter than me have said unless you are actually looking to reinvent the field, there is little benefit to getting into the weeds of the maths. I guarantee you Lewis Hamilton has 0 idea how the craft he pilots works, yet he is still able to hold the record for most F1 wins, ever. You dont know all the details about how something works to push the limits of what is possible with it.
Our new table becomes (once the not described math is applied)
'my' 27287 0.23 0.44 -0.008 0.23 1.44 -0.008
'cat' 28498 0.72 -0.45 0.33 1.56 0.09 1.17
'shat' 47385 0.48 -0.92 0.16 1.39 -1.34 1.07
'on' 7265 0.71 -0.33 0.04 0.85 -1.32 0.18
'a' 27020 -0.77 0.88 0.29 -1.53 0.23 -0.47
'hat' 3828 -0.65 0.01 0.63 -1.61 0.29 -0.33
Attention Calculation is calculated.
The transformer doesn’t just stare at the word vectors and guess what’s important. It projects each word into three new vectors using mini neural networks (well, linear layers):
Query (Q): What am I looking for?
Key (K): What do I offer?
Value (V): What info do I carry?
For every word, the model compares the query of that word with the keys of all other words using dot products. A dot product is a math operation between two lists of numbers that gives you a single output telling you how similar the two lists/vectors are. This tells it how much attention to pay to each other word.
Then it squashes those comparisons with a softmax to get probabilities. A softmax is where we turn a list of numbers into a probability distribution, which is a list of values between 0 and 1 that all add up to 1. I vaguely recall this shit from a stupid uni class I did in summer semester because I was behind in credits. Basically things that are more probable get weighted higher (almost stunningly obvious here). It uses theese probabilities to blend together the values, creating a new vector that mixes in info from all the other tokens depending on relevance.
To recap, in this step we are comparing each word in the sentence against all other words in the sentence to tell us how similar they are, so we know how much attention to pay to particular pairings. Then these comparisons are squeezed into a pd so the sum of all the compariosns equals to 1. Likely pairs bubble up to the surface, as unlikely pairs are weighted poorly.
Layer normalisation is applied.
Vectors are rescaled for each word so its dimenaions have a mean of 0 and a variance of 1. This keeps the inputs to each layer well behaved and stable, preventing exploding or vanishing gradients (use your noodle you can work out what is meant) as the data flows through deepr layers. I will not be explaining how this is done as I quite frankly do not care.
Multiple heads (processes running in parallel w/ diff settings) process the input sentence to in a sense ‘decode’ the meaning.
One head might look at how shat and hat are related, one might look at my and cat. Each head learns a different relationship. The outputs from the heads are concatted together for a final output.
There is a relationship between the size of our vector table and how many heads will be used; the embedding size (aka hidden size) % (modolus) head_count == 0. Basically the number of heads modulused against the hidden size needs to equal 0, there cannot be any remainder. If you have an embedding size that cannot modulus to 0 with any number, you need to change the number of heads, or the hidden size (embeddings) or both.
Since our example has an embedding size of 3, we can use 3 heads, or 1 heads, since 3%3 and 3%1 are both clean, but we can NOT have 2 heads. In reality this is not a good number to use; each heads going to have just a single dimension to look at. A good number is 64 dimensions/embeddings per head. If we look at BERT again, 768/64 == 12. 768 % 12 == 0. Like magic.
The output from the heads is passed through a feedforward neural network.
This is a tiny nn with a ReLU in the middle. Which is Rectified Linear Unit. It basically, not to triviliase it too much, takes any negative inputs and returns 0. Its kinda like an inverse compressor; where a compressor will take anything too positive and crush it to x, ReLU will take anything too negative (ie negative at all) and push it up to 0.
Why on earth would we do this? Without a non-linear activation function (like a ReLU) our little FFNN will, by virtue of NOT being non-linear (ie BEING linear) is just going to stack its linear operations ontop of each other, bigger and bigger, upwards and upwards, like a straight line. This is nice for things such as measuring the relationship between sulphur presence and demonic entities but things like words, semantics and meaning, context, are not linear, simple things to understand. So we need to make our functions “non simple” and able to repersent non linear patterns like curves, corners etc instead of big ass straight lines.
Processed inputs (ie all negatives brought to 0) are added back to the original input of the FFNN.
This helps the model retain the original signal (context from earlier layers), helps prevent the nw forgetting useful patterns, enables gradient flow through the networks.
Here is a GPT generated analogy on gradient flow, because everything I was coming up with it kept saying was wrong. “Think of a conveyor belt of chefs making a dish step by step. If the final dish tastes bad, someone needs to tell the first chef what went wrong. Gradient flow is like a clear message being passed from the food critic (the loss) all the way back to the first chef (early layers), so everyone can adjust how they do their part next time. If the message is too vague or weak along the way, the first chefs won’t know what to fix — and the dish stays bad.”
Remember at their core, NNs are stasticical machines, and a lot of stats is sifting through the data pile and making guesses, but guesses become estimations once we add a little reasoning, a little science and math to them.
Process output n number of times (where n is layer count).
In our case, it is 3 layers. Output from pass 1 is fed as input for pass 2, and pass 2 output is given for pass 3, and so on, but the process from step 5 - 7 is repeated in full for each pass.
FIN
Once we have processed the input through all N layers, were left with another sequence of vectors; one per input token. With this sequence, we can move to output generation. This is not really part of the transformer now, so we will assume the outputter is a magic box capable of giving me gold coins and a good nights rest.

So now we know (in theory) how transformers work. And we could (in theory) patch together our own implementation! But, much like upon finishing the hardware section of NAND2TETRIS, the reality is “you could, but noone does this because it already exists on the shelf”. This is not meant to be disliiusioning, in fact it is freeing. One COULD produce an entire CPU from nand gates, just as one could grab existing components and use them. It all depends what you want. I could use existing research and bookmark management software, or I could put my own together with string and glue. This is like the 4th or 5th time I have mentioned this project without posting it, I will get there.
DEMO
Our little demo, will now use the transformers package. There is a little bit of downloading we must do. Torch, transformers and the little model are approx half a gb. This will visualise the correlation that goes on during the attention mechanism. As we are not doing anything with the outputs as mentioned in step 11, there will be no follow through or response, because that is a very very different topic. Much as reading and writing are linked, they are taught independantly becuase after all, they ARE different topics.
pip install transformers torch matplotlib
Run this python script.
Each square in a heatmap represents how much one token (on the Y-axis) pays attention to another token (on the X-axis).
Brighter = more attention == more “relationship”
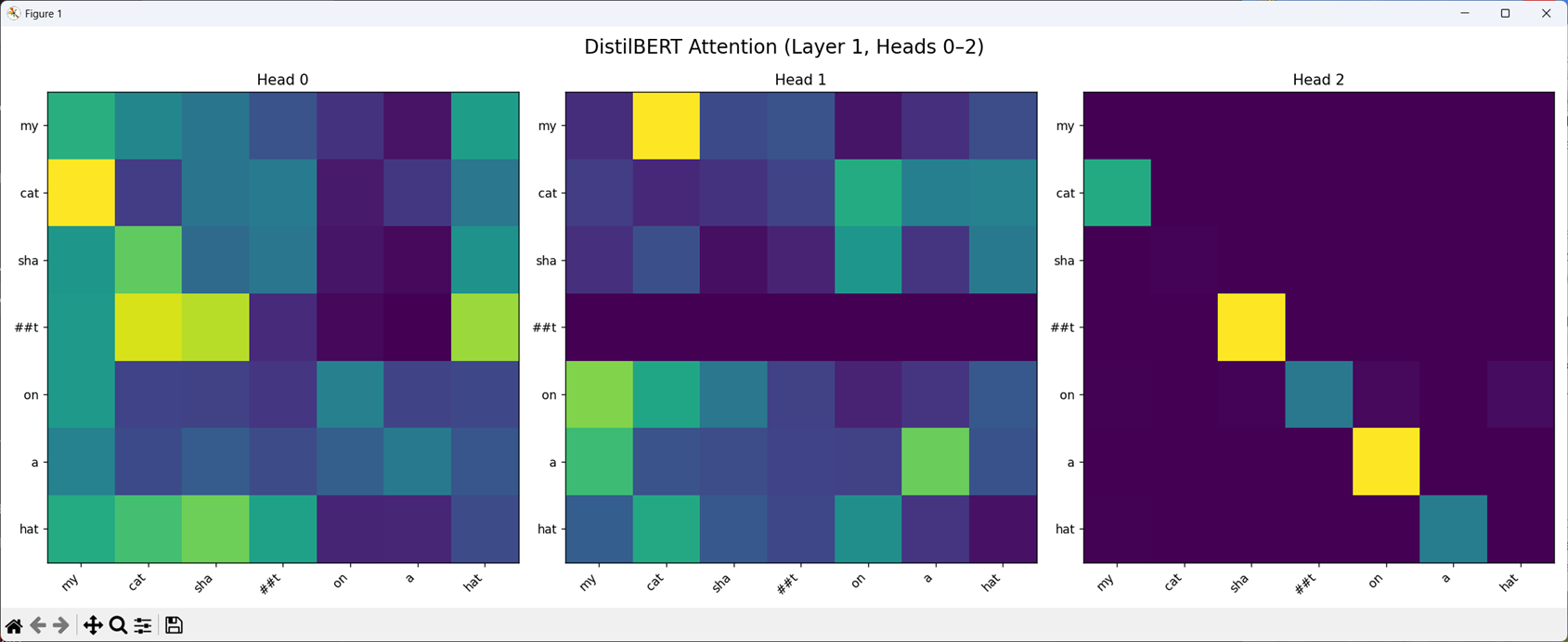
As we can see, shat has been broken up! This is because shat is not in its vocab, so it is being split up into “sub word units”.
What else is cool though is we can see my and cat, as well as cat and my are linked in heads 0 and 1 respectively. It is working!
Let us change shat to shit, and see what happens, since I have a feeling (well given I am writing this after conducting the experiment so I know) that shit should be in the list.
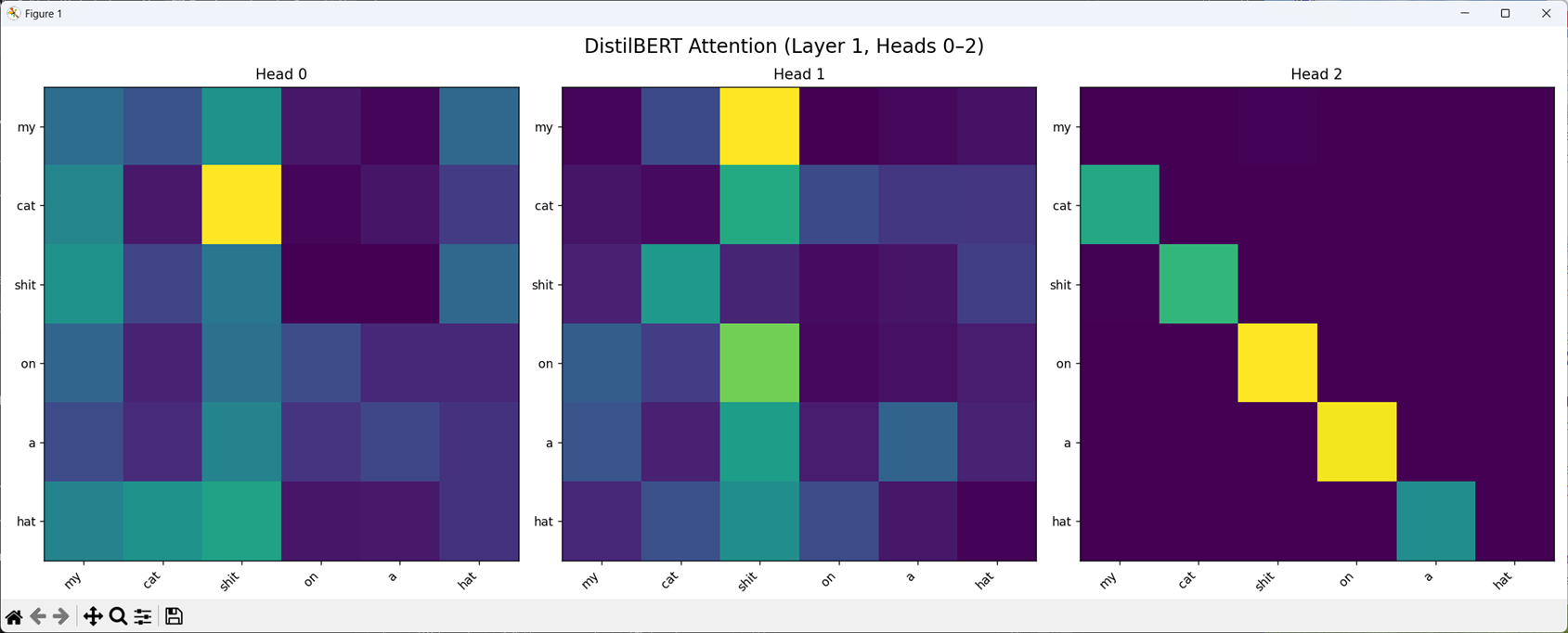
Check it out, theres a corrolation between cat and shit on head 1! And shit and on on head 3! Neat.
This concludes our cursory look into what a transformer is, and is another post Ive been meaning to make since like last October. I am getting better at scrubbing things off the to do list; I finally bought that nice new drill last night I have been meaning to get for ages.
Stay tuned for more halfbaked musings, hopefully the next one will finally be where I post about the workflows (bash and python loops) I have set up that literally make me feel like I have command over the palantir.
