
Plain old patch diffing for CVE-2021-3156
This is not a nutritional blog post. It exists solely to meet requirements for goals I put onto the whiteboard and my brain cant move forward until I have removed it from the board.
I wanted to take a different approach to code review. Rather than “just read the code” to find the bad parts, I wanted to spend some time looking at good and bad code side by side to become enlightened. It worked well when doing my OSWE; the material railroads you into thinking solely about Java and .NET, and the internet was full of people saying the exam was solely going to be Java, so I spent time learning what bad Java patterns looked like via PentesterLabs vulnerable snippets.
But unfortunately it hasnt carried over into me being able to properly read and diagnose code that I havent been explicitly told there is a vuln in. I thought taking the a/b approach would help, and this post does the dual function of ticking off another patch diff for the year. I am sneaky and always look for the easiest way to do something.
OSWE tell us to use grep and diff. These tools certainly work, but for large codebases, not singular pieces of code, that shit gets out of hand. I discovered a tool called meld and I must say it works VERY well. Visually highlight which pages actually have differences, and show you inside the file where the diffs actually are.
Using this, we could actually identify pretty easily where the code we are interested was inserted. Meld shows us that a grand total of 12 files are different between sudo versions 1.9.5p1 and 1.9.5p2. Of these 12, 5 are related to compilation (Makefile, configure etc etc). Click file filters to be able to hide the files that are the same.
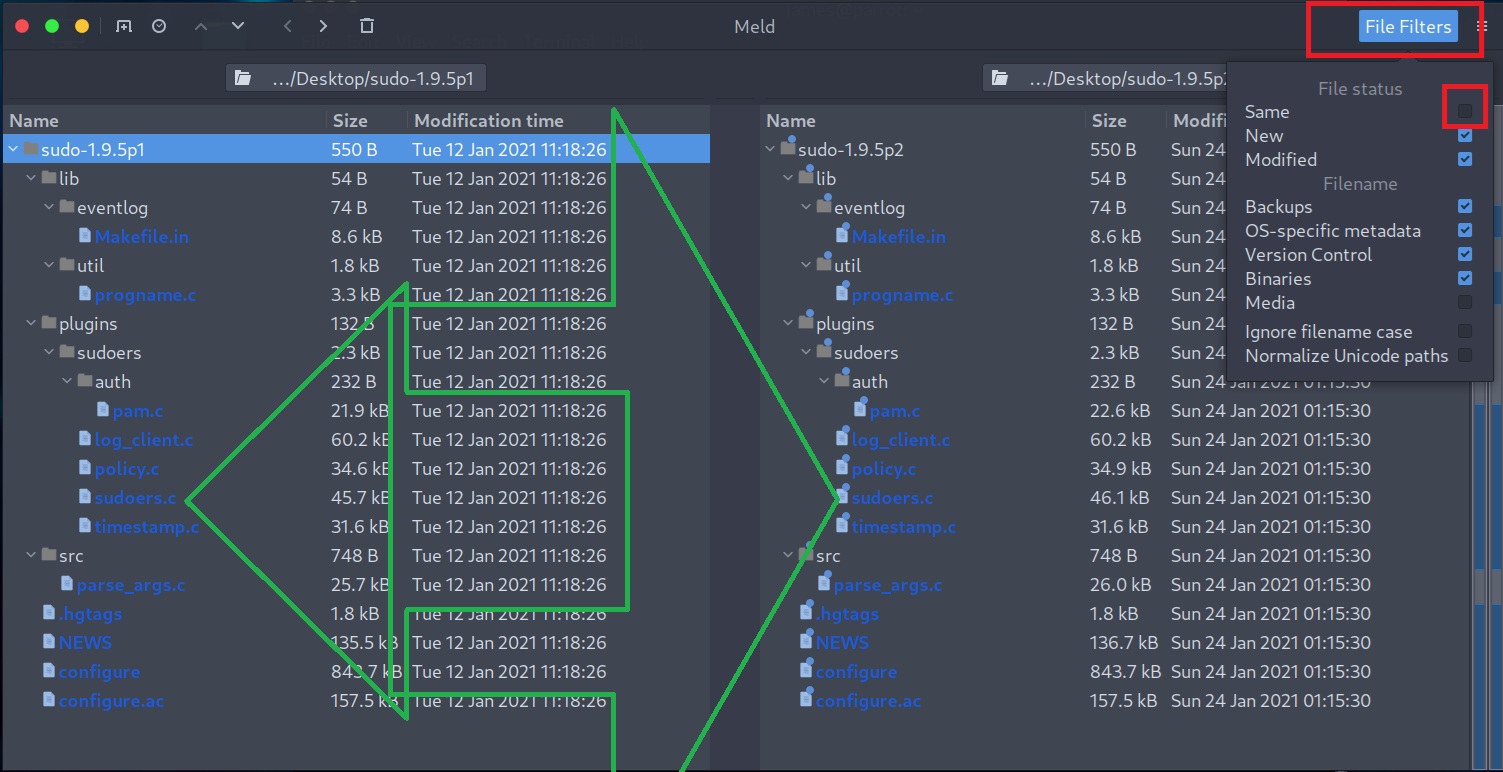
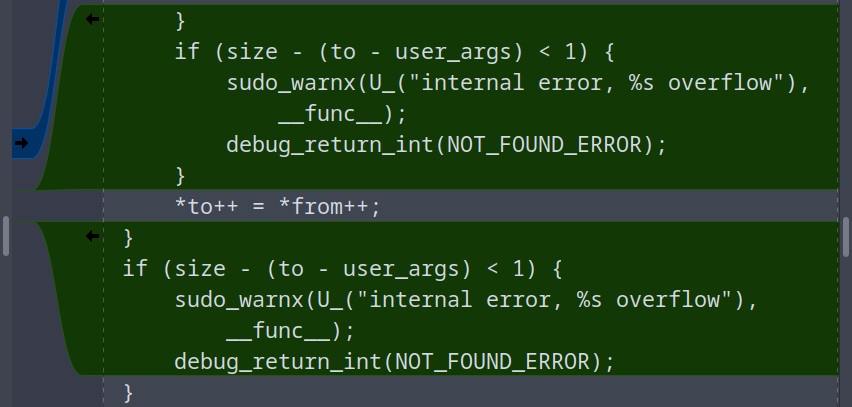
Double click on the sudoers file, since logic is guiding us that since this is a sudo related CVE, the issue is going to be in the sudoers file. Drilling into whats left we find this nice new blob performing a size check on the userargs being sent and prevents a buffer overflow from occuring.
It is still somewhat funny to me that in the year of our lord 2020 + X that we still find buffer overflows. I dunno, maybe I am in the second golden age of computing right now. Appliances are dogshit and seem to be easy prey, cloud is still fucked, FPGAs seem to be the answer to building a 70s microcomputer and not dealing with half a century old hardware, superpowered autocomplete can help me with 80% of my personal projects, the insane amount of compute I have in the garage would have been unthinkable to me as a kid, let alone what I actually work from.
Where are we going with this? Nowhere really. Its a “simple” block to remove any previous conceptions and assumptions regarding the user inputs. Part of the issue here is the use of pointers. * in front of a var means its a pointer. We can see there is a copy happening here with *to++ = *from++;
This is taking from one buffer and putting into another buffer, via the use of pointers. Not a problem, normally. But notice in the pre patch that theres no bounds checking. Theres some unescaping going on, but once thats complete, it just..does it. No checking if the boat is overburdened, it just keeps moving the shit on until it sinks.
What did we take away from this? Essentially, anytime theres pointers involved, we should make a mental note to check if the dev has actually put up bounds checking. If not, well we might be able to squeeze out something..
And that concludes the blog post. You may be saying “wait is that really it?” and the answer is yes! You are correct! This is it. Like I said, this is to fulfil a contractual obligation to produce 3 patch diffing blog posts. I have shit to do man.
