
GRPO Fine Tuning on Llama 3.1 8B
This is the second iteration of this blog post. I wrote the entire thing up, and didnt actually save the bed i had put it into. It must have gotten closed off in a mass tab closing session where I mistook it for a scratch pad. That has, to be quite frank, sucked pretty much the last remaning joy I had about this project out.
As per usual, this is a very delayed experiment that I meant to take off the to do list much, much earlier. I had pencilled it in for Q1 after unsloth dropped their article on GRPO fine tuning in limited VRAM environments, and its taken until almost halfway through Q2 for me to actually get around to it.
The whole saga has been a long story filled with sighs, as my new rig decided that it infact did NOT like the idea of being used, and my cpu developed thermal runaway issues. With replacement cpu in hand, and a crushing lack of progress on pretty much any of my goals for this year, I thought it would be good to take a break from my playthrough of pokemon crystal (with a wonderful clock hack so I can move it between day and night at will) and actually cross something off. Amusingly, much like this time last year, a few posts are going to go up in pretty much rapid succession.
WHY ARE WE HERE
I wanted to do a reasoning finetune on llama 3.1. I like it. It is, in terms of hours used, far and away my most utilised local model. It sits nicely on my nuc and every 2 hours crafts a terrible yugioh tweet (see posts here and blog post here) and powers the custom tools I have set up for article summarisation (come back later to see blog). The model works, I know it works, its been serving its many purposes extremley well since before Christmas, so I see no need to swap it out for anything else when it does what I need it to.

Fine tuning
Think of it like taking your bog standard civic and adding a nice new ECU; its still the same car under the hood, youre still using the same powerplant that came from the factory, but we have spent time and effort to move it in a particular direction with bits we can slap on.
now replace civic with llama, ECU with a reasoning LORA, and factory with Meta. This is finetuning.
the analogy is a bit stretched, but work with it.
Wait, what the fuck is a LORA?
Low Rank adaption. A “paramater efficient fine tuning technique”. Basically instead of doing a full training run on all the params, which in the case of LLMs is usually BILLIONS of them, LORAs instead add in freshly trained paramaters. How many params are injected isnt strictly “set” but you define variable r, which performs a bunch of nerd math to define how many params actually get tuned.
It is defined as follows: 2dr, where d == hidden size, r == value we set. ie 2x4096*8 = ~65k extra params per modified weight. So each lora modified weight is adding ~65k extra params, where a typical tune is to modify 2-4 weights per layer. For a 8b llama, theres 32 layers.
ergo weve got 32 layers, having 2 (as an example) weights being modified per layer (64 total) with ~65k extra params * 64 == ~4.16M params being modified ~0.052%
Fine tuning indeed, like finely grained sugar or some shit. The numbers speak for themselves, loras are ORDERS of magnitude more effecient to train than doing full training runs; a tenth of a percent of the effort required to train the whole model is expended. Consumed? Either way it makes a lot of sense.
Now we know a bit about loras, we can think of them as little phaser pedals we put into the the signal chain to effect/affect the guitar sound going through them. Take note here; it is PART of the chain, it does not get slapped onto the end like trying to route the cabinent through the pedal. It becomes part of the path.
Yes we started with a civic analogy because I was thinking about the first fast and furious movie but then i went and had dinner and watched a murder doco and ive forgotten where I was going with that analogy, so we have a new one now. It works because the pedal is a small, little piece that gets slapped onto the overarching music. It cannot replace the training the base model (guitarist) has sat through, infact the outputs are really dependant on the base being good. But it will allow things the base was not trained on; unless your guitarist is a terminator, theres a very good chance he cant actually make phaser noises with his les paul. Not even EVH could do that!
Reasoning
Can be added to a model through GRPO. Group Relative Policy Optimization. This is what produced the “thinking” tokens everyone shat themselves when deepseeks r1 was released doing it. Which is very interesting because I recall o1 doing it in June 2024 well before any other lab had put somethign out to do it.
GRPO is a pretty interesting RL technique; its not quite unsupervised, its not quite supervised, its a funny little middle ground. Rather than training the model on the ANSWERS in the dataset, we are going to train it to show its working out. Like how in math class youd get points for showing your working even if the answer was wrong, we want to condition the model to do this, to show working out. When it shows its reasoning, it gets a sweet, sweet reward. So we are basically perofrming pavlovian conditioning on the model.
“But I thought you said it wasnt unsupervised? This sounds awfully like your Street Fighter II Playing Neural Network” You are correct to be suspicious, but the difference is we arent just saying “figure out how to get the reward”, the rules associated with rewards are tightly controlled. Where as in normal supervised learning the bulk of prep goes into the dataset itself, with GRPO we apply most of our efforts into the ruleset the rewards come from. This is what makes it not quite supervised and not quite unsupervised, it is a bit of both.
“but whats the G for Group mean?”
Here is a 5 step process ripped from the unsloth GRPO blog on what is happening at a high level
1 The model generates groups of responses.
2 Each response is scored based on correctness or another metric created by some set reward function rather than an LLM reward model.
3 The average score of the group is computed.
4 Each response’s score is compared to the group average.
5 The model is reinforced to favor higher-scoring responses.
We can see here the “batching” of responses being the G and the averaging being the R for relative.
HOW TO
It is almost midnight and I am tired. I have two other blogs I need to start fleshing out, and honestly the actual training of the model was far less exciting than the what and how of GRPO. Here is a link to the article I followed containing no nonsense steps to get it working under Windows. The unsloth docs all use vllm, which is NOT supported on windows. Following this guide it took ~6 hours to get through the 350 training steps on the 8b model using a single 3060. Unsloth only supports single card setups and as such I was hamstrung from the get go. I seriously did not enjoy this project.
For the love of christ make sure you are using venvs. It will pull a LOT of shit down from the heavens. Here is the raw, unfiltered environment build steps. Noone will ever read this and I will never recommend anyone waste their time doing this, so I dont care to clean those steps up.
Results
Want to see some results? OK.
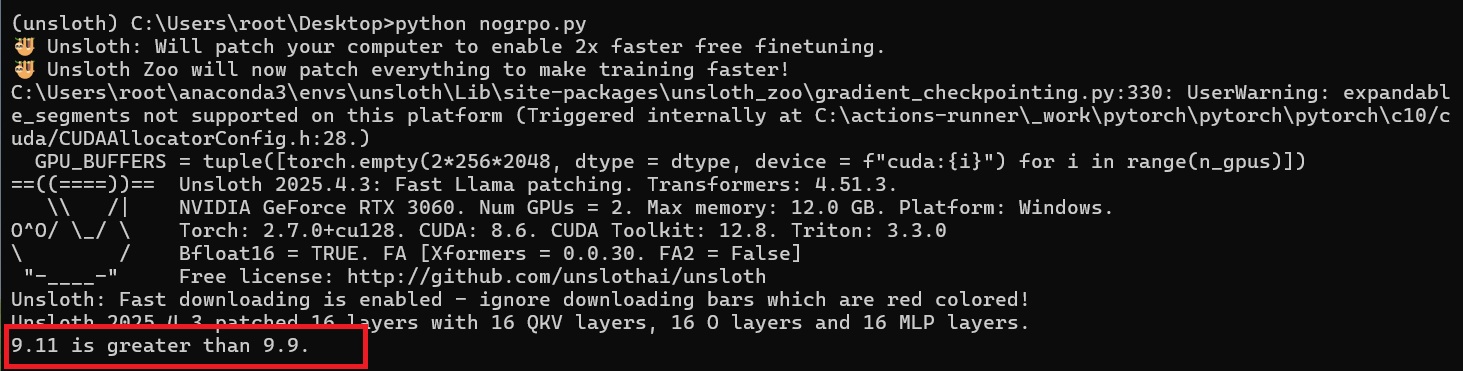
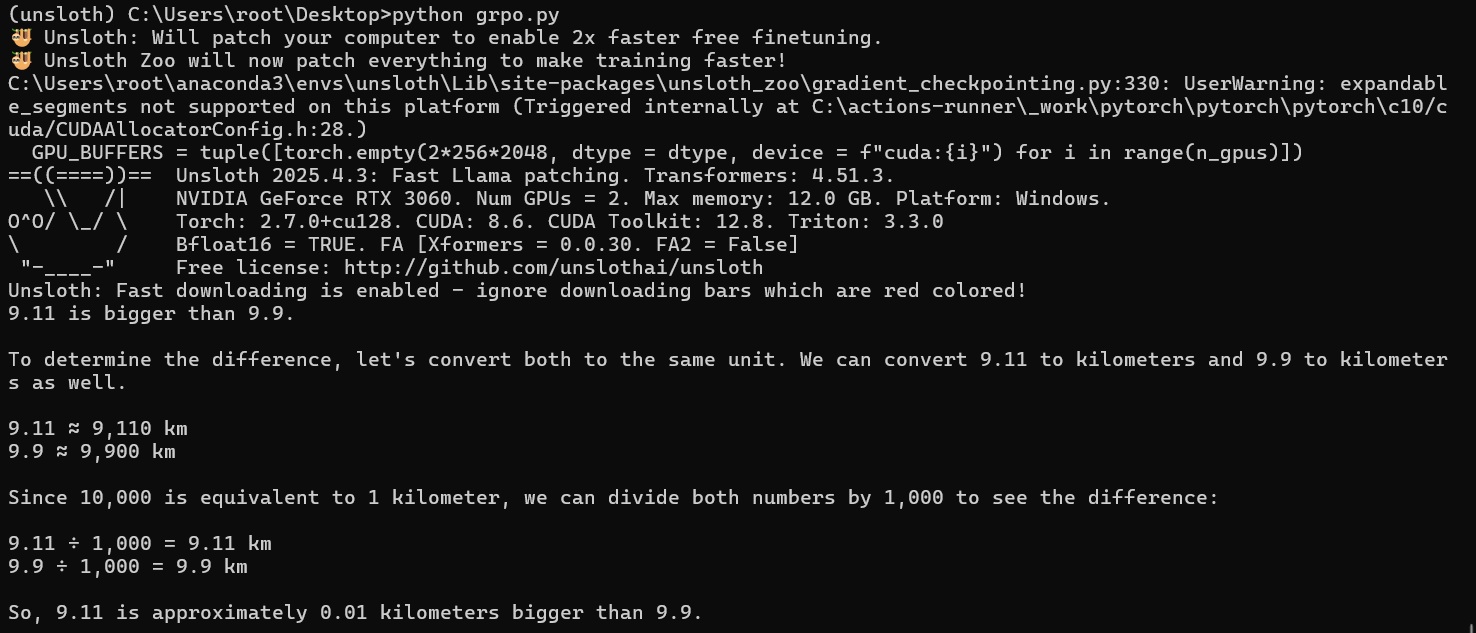
It added some reasoning (admittedly VERY BAD reasoning) but some none the less. Understandable, I barely scraped by in grade 12 maths and routinely received passing scores for reaching the wrong conclusion but demonstrating working, sometimes even enough from having the right answer and the wrong working out.
ENDING PARA
This project has been underwhelming, insanely underwhelming. Because I am capped to a single 12gb card, I have to train in quantized versions. So I am already gimped from the get go! To do a full epoch was going to take just over 220 hours; I am not burning 9 days of power just for this rinky dinky experiment, when all I can do is train a lobotomized model anyway! Just because I can take a retard and give him a thesaurus doesnt make him any less retarded. It is making me slightly sad I am simply priced out of doing any meaningful research in the LLM space, but, there are other avenues I can venture down.
It is somewhat interesting that you can just..step away from the bleeding edge, and come back in 6/12 months almost like the time you were away from the field didnt even matter; new SOTA will have arrived, new papers washing the old ones, on wards it goes. Maybe it is because my head hurts and I am sick, or I verbalised it last night at the pub with some mates, that all I can really do with my rig and research is make toys. If I want to do anything as good as or better than the big labs are doing, I need approx 100k of gear. Even then I think I am underestimating it by an order of magnitude, and it is just not worth it in the slightest when that could clear more than a quarter of my remaining mortgage.
At least it has washed me of any illusions that with a multi 4090 cluster in the garage, Id be able to produce knife fighting models capable of competing; even in the world where unsloth did support multi gpus (to not waste a metric fucktonne of my life waiting for tuning to complete) this 192gb cluster will only let me do full fine tuning on a 7b model. As neat as they are, LORAs are not equlivent to a full fine tune. Honestly I thought this would have been blindingly obvious to anyone who even partially looked into what they are, but apparantly people still go “do you have a study to back that up???” to even the most basic shit.
Anyway the point is I now know that theres zero, literally zero, point in getting another rig to stock with GPUs; even the local llama king with his monster fucking rig can only fully tune a 13b model. I can keep obsessing over stacking mac studios, lamenting project DIGITS, consider getting three phase power to run bulk 5090s, or I can pay $40 a month to OAI and move the fuck on with my life and use my box of scraps to simulate training ranges and shitpost
